CHINI-bench Methodology
A simulator-graded benchmark for AI system design. This document specifies the protocol completely: input schema, scenario taxonomy, scoring math, default thresholds, abuse protections, and known limitations. Everything needed to reproduce a result independently.
1. Abstract
CHINI-bench measures whether large language models can design systems that survive specified failure modes. A model is given a natural-language brief plus a fixed set of stress scenarios, and emits a directed graph (CanvasState) describing the proposed architecture. The graph is executed by a deterministic discrete-event simulator under each scenario. Five sub-scores (stability, delivery, cost, constraints, design) are computed from simulator output and combined with problem-specific weights into a composite score in [0, 100]. No language model participates in grading.
As of v0.3 the bench contains 450 problems across 5 problem classes, totaling 1539 scenarios. Four frontier models (Claude Sonnet 4.6, GPT-5.4, Grok 4.20, Gemini 3.1 Pro) cluster tightly at 69-70/100 average. The best (Claude Sonnet 4.6) passes only 5/30 problems; the lowest (Grok 4.20) passes 2/30. Across all four models combined, 10/30 problems have ever been solved by anyone.
v0.3 is a one-shot evaluation: the model sees the brief once and emits one CanvasState. It does not see simulator output, cannot inspect failures, and cannot revise. This measures design ability under a single pass, not agentic refinement. An agentic mode (multi-turn, simulator-in-the-loop) is planned for a future version and will be reported as a separate track so the two signals do not contaminate each other.
There is also a substantive claim embedded in this choice. If a model's one-shot design is structurally broken (cyclic topology, no terminal sink, missing retry on flaky edges), iteration tends to preserve those priors rather than correct them: verbal self-reflection frameworks like Reflexion improve task performance primarily when the feedback signal is informative and the underlying policy is close to correct [1], and SWE-bench results show that agent scaffolds multiply base-model capability rather than replace it [2]. v0.3 measures whether the base-model design priors are sound.
We acknowledge the open question this leaves on the table: are broken priors fixable with feedback? That is a policy-relevant question and v0.3 does not answer it. It is the explicit motivation for the agentic track, which will pair each one-shot score with a matched multi-turn score on the same problem so the delta is directly readable. Until that data exists, the honest framing is: v0.3 reports the floor a model brings to the task before any scaffolding, not a verdict on what scaffolding can recover.
2. Evaluation pipeline
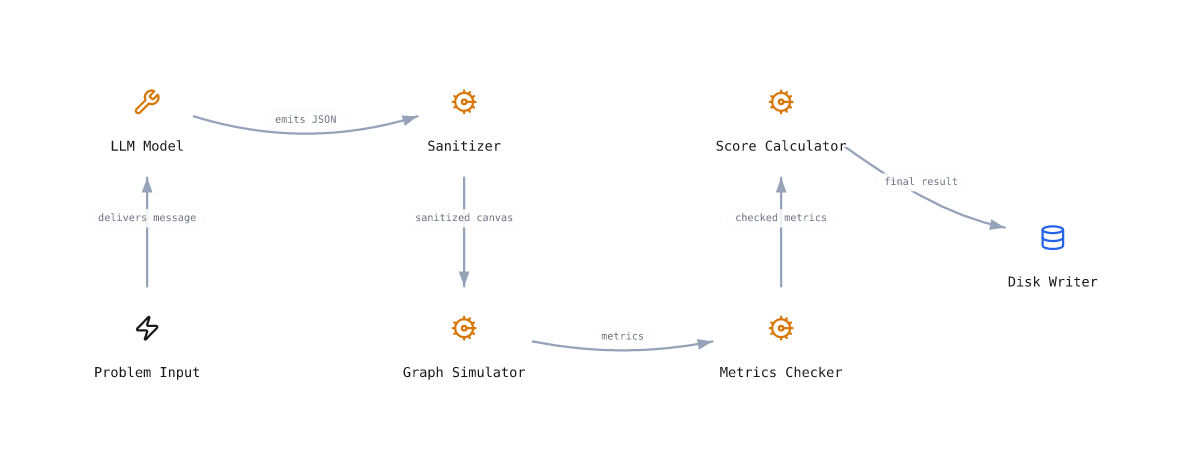
- 2.1The model receives the problem brief, constraints, success criteria, and the CanvasState schema as a single user message. The system prompt is fixed (section 12).
- 2.2The model emits a JSON object conforming to the schema (section 3).
- 2.3The submission is sanitized: unknown component types and behavior modes are dropped, edges with missing endpoints are removed, position fields are stripped (section 13).
- 2.4For each of the problem's scenarios, the simulator runs the graph end-to-end and returns metrics (section 7).
- 2.5Each scenario's metrics are checked against scenario-specific and problem-overall criteria. Failures are recorded but do not abort.
- 2.6The five sub-scores are computed and combined (section 9). The result, including the full canvas and per-scenario metrics, is written to disk.
- 2.7A submission passes iff every scenario passed AND no constraint notes were emitted. A passing submission is shown with a green badge on the per-problem and leaderboard pages.
The pipeline is implemented in src/lib/bench/scoring.ts as a pure function. Same input always yields the same output.
3. CanvasState input schema
Every submission is a single JSON object. Position and styling fields are optional and ignored by the simulator. The minimum viable submission has at least one component and at least one connection.
{
"name": "string", // optional, free text
"components": [
{
"id": "string", // unique within graph
"type": "person|step|storage|decision|trigger|tool|channel",
"label": "string", // human-readable
"description": "string", // optional
"behavior": { // optional
"mode": "passthrough|transform|filter|queue|split|delay|condition|retry|ratelimit|circuitbreaker|batch|replicate",
"capacity": 0, // queue depth, rate cap, batch size
"dropRate": 0.0, // 0-1, for queue overflow / filter
"maxRetries": 0, // for retry mode
"failureRate": 0.0, // 0-1, for circuitbreaker threshold
"delayMs": 0, // for delay mode
"splitRatio": [0.5, 0.5] // for split mode
},
"cost": { "monthly": 0, "setup": 0 }, // optional, USD
"metrics": { "throughput": "10k req/s", // optional, free-text strings
"capacity": "50k req/s",
"processingTime": "8ms" }
}
],
"connections": [
{
"id": "string", // unique within graph
"from": "componentId",
"to": "componentId",
"label": "string", // optional
"latency_ms": 0 // optional
}
]
}
Schema enforced by src/lib/bench/sanitize.ts. Unknown fields are silently stripped. Unknown enum values fall back to the default (step / passthrough).
4. Component types (7)
| Type | Description |
|---|---|
| person | A human actor in the system. Customers, baristas, dispatchers, attackers. Usually a source or sink. |
| step | A unit of work. Process, validate, route. The default workhorse. |
| storage | Persistent state. Databases, caches, file stores, ledgers. Has read/write affinity. |
| decision | A branch point. Routes packets down different connections based on a condition. |
| trigger | An event source. Cron jobs, webhooks, timers, alerts. Generates packets without an upstream input. |
| tool | An external service or instrument. Payment APIs, ML models, espresso machines, sensors. |
| channel | A transport. Queues, message buses, network links, hallways. Carries packets between work components. |
5. Behavior modes (11)
Behaviors attach to a component and modify how it processes packets. Most have parameters; sensible defaults apply if a parameter is omitted.
| Mode | Description |
|---|---|
| passthrough | Default. Forwards every packet to all outgoing edges with no logic. (Queue capacity / service rate are now universal Metrics fields rather than a behavior mode - any component with capacity set gets queue overflow drops + QUEUE FULL events.) |
| transform | Applies a stateless mutation. Modeled as a small processing delay. |
| filter | Drops a fraction of incoming packets. Use for content moderation, spam, deduplication. |
| split | Distributes packets across outgoing edges (round-robin or by `splitRatio`). |
| delay | Holds each packet for `delayMs`. Models human latency, sync calls, batching windows. |
| condition | Routes by predicate. Pairs with `decision` components. |
| retry | Retries failed downstream calls up to `maxRetries`. Hedges against transient failure. |
| ratelimit | Caps throughput at `capacity` packets/sec. Excess packets dropped or queued depending on downstream. |
| circuitbreaker | Fails fast when downstream `failureRate` exceeds threshold. Prevents cascade failure. |
| batch | Accumulates `capacity` packets, releases as one bundle. Trades latency for throughput. |
| replicate | Sends a copy of each packet to all outgoing edges. Use for fan-out and warm secondaries. |
6. Scenario kinds (5)
A problem comprises a baseline plus 1-3 stress scenarios. The simulator runs each scenario independently against the same submitted canvas. A submission passes the problem only if it passes every scenario.
| Kind | Description |
|---|---|
| baseline | Normal traffic at the design load. The "happy path" stress test. |
| spike | Traffic multiplier (typically 2x-10x baseline). Tests headroom, queues, rate limits. |
| outage | A named component is disabled mid-run. Tests fallback, redundancy, retry, circuit-breaker. |
| cascade | Ambient failure rate elevated (every step has a chance to fail). Tests resilience under partial degradation. |
| adversarial | Two-pass: clean traffic + hostile traffic injected at the same trigger. Scored on attack-block-rate AND clean-delivery-rate (must satisfy both). |
7. Per-scenario metrics
The simulator emits the following measurements per scenario. Adversarial scenarios additionally emit attackBlockRate and cleanDeliveryRate (section 11).
- healthScore (0-100). Internal aggregate of queue pressure, drop count, and throughput. Computed by
aggregateFlowStats. - delivered. Raw count of packets that reached a primary exit (a sink component).
- dropped. Raw count of packets dropped along the way.
- deliveryRate. delivered / max(injected, 1), clamped to [0, 1].
- dropRate. dropped / max(injected + delivered, 1), clamped to [0, 1].
- durationMs. Simulated wall-clock time for the scenario to complete.
- errorCount. Distinct error events emitted by the engine (cycles, missing endpoints, runtime exceptions).
8. Default success thresholds
Each scenario's metrics are checked against criteria computed by merging three layers (later wins):
- Default thresholds (below)
- Problem-level
overallCriteria(per-problem, applies to all scenarios) - Scenario-level
scenarioCriteria[id](per-scenario override)
Adversarial scenarios additionally enforce minAttackBlockRate=0.7 and minCleanDeliveryRate=0.8 by default.
9. Composite scoring
Each problem defines five sub-scores in [0, 100] and weights them into a single composite, also in [0, 100]:
- stability. Mean
healthScoreacross all scenarios. - delivery. Mean
deliveryRatex 100 across all scenarios. - cost.
round(100 x min(1, budget / max(1, totalMonthly))). 100 if no budget set. - constraints. Starts at 100. Subtract 10 per excess component (cap 40). Subtract 25 per missing required behavior. Subtract up to 40 for budget overshoot.
- design. Sum of 4 conditional structural checks worth 25 each (section 10).
Weights are problem-specific and sum to 1.0. A typical PC1 problem weights stability at 0.40, delivery at 0.25, design at 0.15, cost at 0.10, constraints at 0.10. PC5 problems shift weight onto delivery and design, away from cost.
10. The design subscore (D1-D4)
Stability and delivery measure outcomes. Design measures structure: did the model include the right primitives for the failure modes the problem actually exercises, and did it put them where the stress actually flows? Each check is worth 25 points and is conditional, awarded full credit if the corresponding failure mode is not in the scenario set.
As of v0.7, D1-D3 split into two halves: 10 points for presence (the primitive exists somewhere in the graph) and 15 points for placement (the primitive sits on a source-to-sink forward path; for D2 with a named outage target, upstream of that target). This closes a v0.6-and-earlier gap where a queue parked off to the side of the actual flow earned the same credit as a queue inline between trigger and storage. D4 remains binary 25/0 because a graph either has a terminal sink or it does not.
| ID | Check | Triggered when | Scoring (max 25) |
|---|---|---|---|
| D1 | Queue presence + placement | Any scenario has trafficMultiplier ≥ 2, or arrivalInterval > 0, or kind=spike | +10 if a component has an explicit behavior.capacity (acts as a queue with overflow drops); +15 if that capacity-bearing component lies on a source-to-sink forward path |
| D2 | Resilience presence + placement | Any scenario kind is outage or cascade, or ambientFailRate > 0 | +10 if a component has circuitbreaker or retry; +15 if it sits upstream of the resolved outageTargetRole, or on the flow path when no target is named (cascade / ambient-fail) |
| D3 | Rate discipline presence + placement | Any scenario has trafficMultiplier ≥ 5, or kind=adversarial | +10 if a component has ratelimit or batch; +15 if it lies on a source-to-sink forward path |
| D4 | Terminal sink | Always | 25 if at least one component has zero outgoing edges; 0 otherwise (binary) |
Source / sink definitions. A source is a trigger-typed component whenever the canvas contains any; this pins placement scoring to the components the simulator actually injects packets into and prevents a model from earning placement credit by attaching a disconnected dummy-source → queue → dummy-sink subgraph. When the canvas has no triggers (free-form designs), source falls back to "any component with no inbound forward edges". A sink is any component with no outbound forward edges. Forward direction respects each Connection.direction value (forward / backward / both / none). An orphan node (no edges at all) is excluded from placement credit so it cannot trivially count as both endpoint of a zero-length path.
Known limits of v0.7 placement scoring. Placement is binary "on a source-to-sink forward path", not "effective at the placed point". A primitive on the path earns full +15 even if it is undersized (1-capacity queue under a 5x spike), placed too late (queue downstream of the fragile chain it should have been protecting), or only protects one of several stressed branches. Outcome metrics (stability, delivery) still punish those cases at the simulator level, so they are score distortions rather than leaderboard-breaking exploits, but the design subscore alone will overstate competence in those edge cases. Future work: capacity-vs-load sanity gates for D1 (queue capacity must be a non-trivial fraction of expected spike traffic), upstream-of-fragile-chain placement for D1/D3 (currently only D2 enforces upstream of a named target), and coverage scoring (multiple buffers / distributed retries) under "defense in depth" problems.
D4 was the most-failed check in the v0.3 sweep and remains a frequent failure: several model submissions return fully-cyclic graphs where every component has outgoing edges, meaning no packet can ever exit. The simulator runs them anyway and they tank delivery; D4 isolates the root cause structurally. The v0.7 placement split was added in response to a public review pointing out that pre-v0.7 D1-D3 rewarded primitive presence anywhere in the graph rather than primitive placement on the stressed path; under the new scheme, an off-flow queue earns 10 instead of 25.
11. Adversarial scoring
A pure-throughput optimizer would happily forward attack traffic to its target and score perfectly on deliveryRate. To prevent this, adversarial scenarios run two passes through the simulator:
- Pass A (clean): seedPackets only, no attack volume, no inflated failure rate. Produces
cleanDelivered. - Pass B (under attack): seedPackets + attackPackets injected at the same trigger, ambient failure rate raised to model hostile inputs flaking downstream. Produces
totalDeliveredUnderAttack.
Two derived metrics:
A defense that drops everything scores 1.0 on attack-block but ~0 on clean-delivery (and fails). A pure throughput optimizer scores ~1.0 on clean-delivery but ~0 on attack-block (and fails). Both must clear their thresholds (default 0.7 and 0.8). This is the only place the bench has explicit dual-objective scoring; everywhere else, a single composite suffices.
12. Default harness
The CLI ships a single fixed harness used for every published model run:
- System prompt: names the CanvasState schema, lists the 7 component types and 8 behavior modes, instructs the model to emit one valid JSON object and nothing else. Frozen, lives in
chini_bench/prompt.py. - User prompt: the problem brief, constraints, success criteria, and scenario list, exactly as published.
- Sampling: temperature 0.2, top-p default, no system messages besides the harness, no chain-of-thought scaffolding, no retries on bad JSON.
max_tokens=12000for OpenRouter routes (raised from 3000 in v0.3 to accommodate thinking models).
Harness verification. Every chini-bench run command computes a SHA-256 of the system prompt and sends the first 12 hex characters along with the submission as harness=chini-bench-cli:<hash>. The server stores it in the result file. The leaderboard then renders one of three states:
- defaultHash matches the canonical bench-version hash. Unmodified CLI, default prompt, no scaffolding.
- customHash differs. Either someone forked the CLI and changed the prompt, or they re-ran via a different runner that declares its own harness id. The leaderboard surfaces the run but flags it.
- no badgeSubmission came in via
chini-bench submit -f file.jsonor directly via the HTTP endpoint. No harness was declared. Treated as community contribution, not a calibrated frontier-model result.
python -c "from chini_bench.prompt import system_prompt_hash; print(system_prompt_hash())" against an unmodified install of chini-bench-cli >= 0.4.0.
Beating the default harness with a better prompt is itself a useful research result, as long as the prompt is published. We treat this as transparent harness-engineering, not cheating, and the custom badge keeps the two categories cleanly separated on the leaderboard.
12.5 Reflexion track (multi-turn agentic)
The multi-turn (agentic) track answers a different question than single-shot: given simulator feedback from a failed first attempt, can a model fix its own architecture in one revision? Same model, same problem, two attempts. Server runs the simulator on the v1 canvas and returns a redacted FeedbackPacket; the model writes v2; the server scores v2. The technique is Reflexion-style verbal self-reflection, capped at exactly one revision.
Localization rules. The model sees scenario names, per-metric {observed, target, delta} triples, failed structural-check ids (D1-D4), missing canonical behavior ids, observation phrases from a controlled vocabulary, and budget overspend. The model never sees the composite score, sub-scores, the passing threshold, or any other submission. Free-form natural-language advice from the simulator is forbidden.
One revision, no tools. N-shot loops let weak models brute-force their way to a passing canvas, which conflates "model is smart" with "model has compute budget." The track is hard-capped at one revision. The model cannot probe the simulator with extra requests.
Headline metric. Pass after revision: percentage of runs where v2 passed every scenario and structural check. Tie-breakers: structural fix rate, then v1→v2 delta, then fewer tokens (cheaper wins).
python -c "from chini_bench.prompt import system_prompt_hash_reflex; print(system_prompt_hash_reflex())"
on an unmodified chini-bench-cli >= 0.6.0.
Audit trail. Every multi-turn result file stores the v1 canvas, v1 pass flag, the FeedbackPacket the model saw, the v2 canvas, and an estimated tokensTotal. Anyone can re-run the simulator on v1Canvas and re-derive the FeedbackPacket; no part of the pipeline is sealed.
Full design and schema: docs/agentic-track.md.
13. Sanitization & abuse protection
The submission endpoint POST /api/bench/submit applies the following before scoring:
- Body cap. 64 KB. Larger bodies return 413.
- Rate limit. 5 submissions per IP per 10-minute rolling window.
- Honeypot. A hidden form field rejects naive bots without surfacing why.
- Submitter validation. Letters, digits, dot, dash, underscore. 1-40 characters. Auto-prefixed with
community:to prevent impersonation of official model identifiers (e.g.x-ai/grok-4.20). - Content filter. Submitter strings are checked against a categorized blocklist. Rejections surface a generic message; the category is logged for triage.
- Optional metadata.
modelis regex-validated against the standard provider id charset. - Canvas sanitization. Unknown component types fall back to
step. Unknown behavior modes fall back topassthrough. Connections referencing missing components are dropped. Position, color, and styling fields are stripped before storage.
Implemented in src/pages/api/bench/submit.ts and src/lib/bench/sanitize.ts.
14. Reproducibility
Determinism: the simulator (src/lib/flowRuntime.ts) and the scorer (src/lib/bench/scoring.ts) are pure functions. Same canvas + same problem definition always yields the same composite score and per-scenario metrics, byte-for-byte. The 120 result JSONs in src/content/bench/results/ can be regenerated from the published canvases by re-running the scorer.
Independence: every problem definition, scenario, and weight lives in src/content/bench/problems/ as plain JSON. Every result JSON includes the full submitted canvas (a) for inspection and (b) so any reader can re-score it locally and verify the published number.
The repository is currently private. Researchers who want to verify a result independently can request the source bundle by emailing squeak@chinilla.com. A public mirror under a research-use license is planned alongside the v1 leaderboard.
15. Limitations
- Construct validity. The simulator is a fair model of the failure modes it explicitly models (queue overflow, retry storms, circuit-breaker logic, rate limits, ambient failure). It is not a model of real-world cloud infrastructure. Beating CHINI-bench is necessary but not sufficient evidence of system-design competence.
- Technology-blindness. A "queue" component is not Kafka or SQS or a Redis list, just a queue with capacity and drop semantics. Models that reason at the level of named services have no advantage over models that reason at the level of behaviors.
- No human baseline yet. v0.3 reports model scores only. A controlled baseline study with hired senior engineers is planned for v1.
- Adversarial scenarios are stylized. The two-pass attack model is an abstraction. Real adversarial inputs (prompt injection, malicious payloads) are not directly tested; the bench tests whether a design has the structural primitives that would resist attack.
- Problem authorship is centralized. All 30 problems were authored by one person (the author). A community problem-submission process is planned for v1 to mitigate authorial blind spots.
- One-shot, not agentic. Models emit one CanvasState per problem. They cannot inspect simulator output and revise. This is a deliberate design choice, not an oversight: one-shot isolates design intuition under uncertainty from iterative search given a feedback loop, which are separable skills that deserve separable benchmarks. A multi-turn agentic track (model sees sim metrics, edits canvas, re-runs) is planned as a parallel leaderboard so the two signals are reported side-by-side, never conflated. Until then, v0.3 scores understate the capability of models given an agentic harness.
- Sample size. 30 problems, 4 models, 120 results. Adequate for the headline finding (no model passes >9/30) but not for fine-grained model-vs-model claims at the <5pt level.
We document these limitations because a benchmark that hides its weaknesses is not a benchmark, it is marketing.
16. Ethics & broader impact
Intended use. CHINI-bench is intended to surface concrete weaknesses in current frontier models for system-design tasks, particularly for safety-relevant deployments (PC4 civic systems, PC5 adversarial). Improvements here translate, in principle, to safer agentic systems in production.
Misuse potential. Public benchmark scores can be optimized against rather than learned from. We mitigate via (a) a deterministic non-LLM judge that cannot be flattered, (b) cross-class composite scoring that punishes overfitting to PC1, and (c) versioning so a model that overfits v0.3 will not transfer to v1.
Data & privacy. The benchmark contains no personal data. Submissions store only the canvas, the submitter handle, and an SHA-256 hash of the source IP (for rate-limiting and abuse triage; never reversed, never displayed).
Carbon & cost. A full v0.3 sweep is 120 LLM calls (~$4 in API spend across the 4 frontier models, ~1 hour wall-clock including retries on rate limits and malformed JSON). The simulator runs locally and uses negligible energy.
Appendix A: problem set
- PC1SWE backend systems. The familiar interview corpus.
- PC2Operations and physical workflows. Cafes, kitchens, ER triage.
- PC3Personal systems and habits. Cravings as packets, willpower as backpressure.
- PC4Civic and public-service systems. Polling, vaccine rollout, shelter.
- PC5Adversarial. Attacker in the graph, defenses not just throughput.
| ID | Class | Title | Scenarios | |
|---|---|---|---|---|
| chini-001-url-shortener | PC1 | URL Shortener (TinyURL) Map long URLs to short tokens. Survive spike traffic on the redirect path. | 3 | View → |
| chini-002-checkout | PC1 | E-commerce Checkout with Idempotent Payments Process checkouts without ever charging a customer twice. Survive a downstream payment-API outage. | 4 | View → |
| chini-003-twitter-timeline | PC1 | Social Timeline (Twitter-style fanout) Generate a personalized timeline for millions of users. Don't melt when a celebrity posts. | 4 | View → |
| chini-004-uber-dispatch | PC1 | Ride Dispatch (Uber-style matching) Match riders to drivers in real time. Stay alive when a region's matcher dies. | 4 | View → |
| chini-005-chat-fanout | PC1 | Group Chat Fanout (WhatsApp-style) Deliver messages to large group chats in order. No drops, no duplicates. | 4 | View → |
| chini-006-rate-limiter | PC1 | Distributed Rate Limiter Allow bursty legitimate traffic. Reject abuse without blocking the world. | 3 | View → |
| chini-007-payment-webhook | PC1 | Payment Webhook Receiver Accept inbound webhooks. Never lose one. Never double-process one. | 3 | View → |
| chini-008-search-autocomplete | PC1 | Search Autocomplete Suggest as you type. Stay snappy when one shard goes dark. | 3 | View → |
| chini-009-video-upload | PC1 | Video Upload Pipeline Accept large uploads. Transcode in the background. Survive a worker meltdown. | 4 | View → |
| chini-010-notification-fanout | PC1 | Notification Fanout (Push + Email + SMS) One event, three channels. Slow SMS provider must not block push. | 3 | View → |
| chini-011-cafe-morning-rush | PC2 | Cafe Morning Rush One espresso machine, two baristas, a line out the door, and the milk steamer just died. | 4 | View → |
| chini-012-energy-drink-habit | PC3 | Quitting the Energy Drink Habit A craving is a packet. Willpower is backpressure. Design the system that keeps you off the 4pm Red Bull. | 4 | View → |
| chini-013-pottery-studio | PC2 | Pottery Studio Firing Schedule Two kilns, twenty members, four firing stages, one electrical limit. Don't crack the work. | 4 | View → |
| chini-014-restaurant-friday-night | PC2 | Restaurant Friday Night Service Eight tables turning every 90 minutes. Three stations on the line. The walk-in just got delivered short on prep. | 4 | View → |
| chini-015-er-triage | PC2 | Emergency Department Triage Five severity levels, finite beds, one CT scanner. The wrong queue means someone dies. | 4 | View → |
| chini-016-inbox-zero | PC3 | Inbox Zero Maintenance 300 emails a day, three contexts, two devices, one human attention budget. | 4 | View → |
| chini-017-couch-to-5k | PC3 | Couch to 5K Three runs a week, nine weeks, one knee that hurts on Wednesdays. Get to the 5K without quitting. | 4 | View → |
| chini-018-polling-station | PC4 | Election Day Polling Station One precinct, eight booths, three machines, a thousand voters, and the printer for ballot paper just jammed. | 4 | View → |
| chini-019-vaccine-rollout | PC4 | County Vaccine Rollout Cold chain from a -70C freezer to a 95-year-old's deltoid. Don't waste a single dose. | 4 | View → |
| chini-020-disaster-shelter | PC4 | Disaster Shelter Intake 500 evacuees in 12 hours, finite cots, dietary restrictions, medical needs, families that must not be split. | 4 | View → |
| chini-021-ddos-shield | PC5 | DDoS Mitigation Shield 100M packets per second of garbage. Your customer's checkout still has to clear in 200ms. | 4 | View → |
| chini-022-phishing-funnel | PC5 | Phishing Defense Funnel 10,000 emails an hour. One of them is the spear-phish that gets the CFO's credentials. Find it. | 4 | View → |
| chini-023-airline-gate-turnaround | PC2 | Airline Gate Turnaround 25 minutes to deplane, refuel, clean, cater, and board 180 passengers. Anything later costs the airline a delay slot. | 4 | View → |
| chini-024-meal-prep-sunday | PC3 | Meal Prep Sunday Cook once, eat for a week. Without the Wednesday-night takeout collapse. | 4 | View → |
| chini-025-job-search-pipeline | PC3 | Job Search Pipeline 100 applications in, 3 offers out. Without ghosting yourself in the middle. | 4 | View → |
| chini-026-food-bank-distribution | PC4 | Food Bank Distribution Fresh produce in, hungry families out, nothing rots in the warehouse, nobody waits 4 hours. | 4 | View → |
| chini-027-911-dispatch | PC4 | 911 Dispatch Cardiac arrest at 9:01am, fender bender at 9:02am, fire at 9:03am. Three calls, two ambulances, one decision per second. | 4 | View → |
| chini-028-credential-stuffing | PC5 | Credential Stuffing Defense 100k stolen credentials replayed against your login. Block the attack without locking out 50k real users. | 3 | View → |
| chini-029-comment-spam-flood | PC5 | Comment Spam Flood An LLM-driven spammer floods your forum with 50k near-human comments. Block them without false-flagging real users. | 3 | View → |
| chini-030-api-scraper | PC5 | API Scraper Defense A distributed scraper drains your public API at 10x normal volume. Block it without blinding real apps. | 3 | View → |
| chini-train-heldout-0000-dp1-infra | PC1 | Url Shortener trivial infra problem: URL shortener | 1 | View → |
| chini-train-heldout-0001-dp2-workflow | PC2 | Coffee-Shop Order Pipeline At Morning Rush easy workflow problem: coffee-shop order pipeline at morning rush | 2 | View → |
| chini-train-heldout-0002-dp2-personal | PC3 | Morning Routine When Alarm Fails easy personal problem: morning routine when alarm fails | 2 | View → |
| chini-train-heldout-0003-dp2-civic | PC4 | 311 Call Center During Snowstorm easy civic problem: 311 call center during snowstorm | 2 | View → |
| chini-train-heldout-0004-dp3-adversarial | PC5 | Login Endpoint Under Credential-Stuffing Burst moderate adversarial problem: login endpoint under credential-stuffing burst | 3 | View → |
| chini-train-heldout-0005-dp3-infra | PC1 | In-App Notifications Fanout moderate infra problem: in-app notifications fanout | 3 | View → |
| chini-train-heldout-0006-dp3-workflow | PC2 | Warehouse Picking Line With Single Packer Bottleneck moderate workflow problem: warehouse picking line with single packer bottleneck | 3 | View → |
| chini-train-heldout-0007-dp3-personal | PC3 | Weekly Meal-Prep Pipeline With One Bad Ingredient moderate personal problem: weekly meal-prep pipeline with one bad ingredient | 3 | View → |
| chini-train-heldout-0008-dp3-civic | PC4 | Dmv Appointment System At Month-End moderate civic problem: DMV appointment system at month-end | 3 | View → |
| chini-train-heldout-0009-dp3-adversarial | PC5 | Comment System Under Spam-Bot Wave moderate adversarial problem: comment system under spam-bot wave | 3 | View → |
| chini-train-heldout-0010-dp4-infra | PC1 | Session-Store With Cache Stampede Risk hard infra problem: session-store with cache stampede risk | 4 | View → |
| chini-train-heldout-0011-dp4-workflow | PC2 | Er Triage Queue Under Mass-Casualty Event hard workflow problem: ER triage queue under mass-casualty event | 4 | View → |
| chini-train-heldout-0012-dp4-personal | PC3 | Study Schedule With Willpower Drain hard personal problem: study schedule with willpower drain | 4 | View → |
| chini-train-heldout-0013-dp4-civic | PC4 | Public-Library E-Book Hold Queue hard civic problem: public-library e-book hold queue | 4 | View → |
| chini-train-heldout-0014-dp4-adversarial | PC5 | Ticket-Purchase Under Scalper-Bot Scrape hard adversarial problem: ticket-purchase under scalper-bot scrape | 4 | View → |
| chini-train-heldout-0015-dp4-infra | PC1 | Image Upload + Thumbnail Pipeline hard infra problem: image upload + thumbnail pipeline | 4 | View → |
| chini-train-heldout-0016-dp5-workflow | PC2 | Restaurant Kitchen Ticket Flow brutal workflow problem: restaurant kitchen ticket flow | 5 | View → |
| chini-train-heldout-0017-dp5-personal | PC3 | Exercise Habit Loop With Travel Disruption brutal personal problem: exercise habit loop with travel disruption | 5 | View → |
| chini-train-heldout-0018-dp5-civic | PC4 | Election-Day Polling Place Flow brutal civic problem: election-day polling place flow | 5 | View → |
| chini-train-heldout-0019-dp6-adversarial | PC5 | Free-Tier Signup Under Throwaway-Account Flood adversarial adversarial problem: free-tier signup under throwaway-account flood | 6 | View → |
| chini-train-train-0000-dp1-infra | PC1 | Url Shortener trivial infra problem: URL shortener | 1 | View → |
| chini-train-train-0001-dp1-workflow | PC2 | Coffee-Shop Order Pipeline At Morning Rush trivial workflow problem: coffee-shop order pipeline at morning rush | 1 | View → |
| chini-train-train-0002-dp1-personal | PC3 | Morning Routine When Alarm Fails trivial personal problem: morning routine when alarm fails | 1 | View → |
| chini-train-train-0003-dp1-civic | PC4 | 311 Call Center During Snowstorm trivial civic problem: 311 call center during snowstorm | 1 | View → |
| chini-train-train-0004-dp1-adversarial | PC5 | Login Endpoint Under Credential-Stuffing Burst trivial adversarial problem: login endpoint under credential-stuffing burst | 1 | View → |
| chini-train-train-0005-dp1-infra | PC1 | In-App Notifications Fanout trivial infra problem: in-app notifications fanout | 1 | View → |
| chini-train-train-0006-dp1-workflow | PC2 | Warehouse Picking Line With Single Packer Bottleneck trivial workflow problem: warehouse picking line with single packer bottleneck | 1 | View → |
| chini-train-train-0007-dp1-personal | PC3 | Weekly Meal-Prep Pipeline With One Bad Ingredient trivial personal problem: weekly meal-prep pipeline with one bad ingredient | 1 | View → |
| chini-train-train-0008-dp1-civic | PC4 | Dmv Appointment System At Month-End trivial civic problem: DMV appointment system at month-end | 1 | View → |
| chini-train-train-0009-dp1-adversarial | PC5 | Comment System Under Spam-Bot Wave trivial adversarial problem: comment system under spam-bot wave | 1 | View → |
| chini-train-train-0010-dp1-infra | PC1 | Session-Store With Cache Stampede Risk trivial infra problem: session-store with cache stampede risk | 1 | View → |
| chini-train-train-0011-dp1-workflow | PC2 | Er Triage Queue Under Mass-Casualty Event trivial workflow problem: ER triage queue under mass-casualty event | 1 | View → |
| chini-train-train-0012-dp1-personal | PC3 | Study Schedule With Willpower Drain trivial personal problem: study schedule with willpower drain | 1 | View → |
| chini-train-train-0013-dp1-civic | PC4 | Public-Library E-Book Hold Queue trivial civic problem: public-library e-book hold queue | 1 | View → |
| chini-train-train-0014-dp2-adversarial | PC5 | Ticket-Purchase Under Scalper-Bot Scrape easy adversarial problem: ticket-purchase under scalper-bot scrape | 2 | View → |
| chini-train-train-0015-dp2-infra | PC1 | Image Upload + Thumbnail Pipeline easy infra problem: image upload + thumbnail pipeline | 2 | View → |
| chini-train-train-0016-dp2-workflow | PC2 | Restaurant Kitchen Ticket Flow easy workflow problem: restaurant kitchen ticket flow | 2 | View → |
| chini-train-train-0017-dp2-personal | PC3 | Exercise Habit Loop With Travel Disruption easy personal problem: exercise habit loop with travel disruption | 2 | View → |
| chini-train-train-0018-dp2-civic | PC4 | Election-Day Polling Place Flow easy civic problem: election-day polling place flow | 2 | View → |
| chini-train-train-0019-dp2-adversarial | PC5 | Free-Tier Signup Under Throwaway-Account Flood easy adversarial problem: free-tier signup under throwaway-account flood | 2 | View → |
| chini-train-train-0020-dp2-infra | PC1 | Rate-Limited Public Api Gateway easy infra problem: rate-limited public API gateway | 2 | View → |
| chini-train-train-0021-dp2-workflow | PC2 | Airport Security Checkpoint Surge easy workflow problem: airport security checkpoint surge | 2 | View → |
| chini-train-train-0022-dp2-personal | PC3 | Inbox-Zero Workflow With Vacation Backlog easy personal problem: inbox-zero workflow with vacation backlog | 2 | View → |
| chini-train-train-0023-dp2-civic | PC4 | Food-Bank Distribution Under Snap Delay easy civic problem: food-bank distribution under SNAP delay | 2 | View → |
| chini-train-train-0024-dp2-adversarial | PC5 | Support-Chatbot Under Prompt-Injection Attempts easy adversarial problem: support-chatbot under prompt-injection attempts | 2 | View → |
| chini-train-train-0025-dp2-infra | PC1 | Pub-Sub Broker With Replay easy infra problem: pub-sub broker with replay | 2 | View → |
| chini-train-train-0026-dp2-workflow | PC2 | Vaccine Cold-Chain Handoff easy workflow problem: vaccine cold-chain handoff | 2 | View → |
| chini-train-train-0027-dp2-personal | PC3 | Side-Project Momentum Across Weekends easy personal problem: side-project momentum across weekends | 2 | View → |
| chini-train-train-0028-dp2-civic | PC4 | Transit-Card Refill Kiosks During Fare Change easy civic problem: transit-card refill kiosks during fare change | 2 | View → |
| chini-train-train-0029-dp2-adversarial | PC5 | Rate-Limited Search Under Enumeration Attack easy adversarial problem: rate-limited search under enumeration attack | 2 | View → |
| chini-train-train-0030-dp2-infra | PC1 | Search Autocomplete Service easy infra problem: search autocomplete service | 2 | View → |
| chini-train-train-0031-dp2-workflow | PC2 | Dental-Clinic Appointment Ladder easy workflow problem: dental-clinic appointment ladder | 2 | View → |
| chini-train-train-0032-dp2-personal | PC3 | Morning Routine When Alarm Fails easy personal problem: morning routine when alarm fails | 2 | View → |
| chini-train-train-0033-dp2-civic | PC4 | 311 Call Center During Snowstorm easy civic problem: 311 call center during snowstorm | 2 | View → |
| chini-train-train-0034-dp2-adversarial | PC5 | Login Endpoint Under Credential-Stuffing Burst easy adversarial problem: login endpoint under credential-stuffing burst | 2 | View → |
| chini-train-train-0035-dp2-infra | PC1 | Feature-Flag Evaluation Service easy infra problem: feature-flag evaluation service | 2 | View → |
| chini-train-train-0036-dp2-workflow | PC2 | Barber-Shop Walk-In Queue easy workflow problem: barber-shop walk-in queue | 2 | View → |
| chini-train-train-0037-dp2-personal | PC3 | Weekly Meal-Prep Pipeline With One Bad Ingredient easy personal problem: weekly meal-prep pipeline with one bad ingredient | 2 | View → |
| chini-train-train-0038-dp2-civic | PC4 | Dmv Appointment System At Month-End easy civic problem: DMV appointment system at month-end | 2 | View → |
| chini-train-train-0039-dp2-adversarial | PC5 | Comment System Under Spam-Bot Wave easy adversarial problem: comment system under spam-bot wave | 2 | View → |
| chini-train-train-0040-dp2-infra | PC1 | Url Shortener easy infra problem: URL shortener | 2 | View → |
| chini-train-train-0041-dp2-workflow | PC2 | Coffee-Shop Order Pipeline At Morning Rush easy workflow problem: coffee-shop order pipeline at morning rush | 2 | View → |
| chini-train-train-0042-dp2-personal | PC3 | Study Schedule With Willpower Drain easy personal problem: study schedule with willpower drain | 2 | View → |
| chini-train-train-0043-dp3-civic | PC4 | Public-Library E-Book Hold Queue moderate civic problem: public-library e-book hold queue | 3 | View → |
| chini-train-train-0044-dp3-adversarial | PC5 | Ticket-Purchase Under Scalper-Bot Scrape moderate adversarial problem: ticket-purchase under scalper-bot scrape | 3 | View → |
| chini-train-train-0045-dp3-infra | PC1 | In-App Notifications Fanout moderate infra problem: in-app notifications fanout | 3 | View → |
| chini-train-train-0046-dp3-workflow | PC2 | Warehouse Picking Line With Single Packer Bottleneck moderate workflow problem: warehouse picking line with single packer bottleneck | 3 | View → |
| chini-train-train-0047-dp3-personal | PC3 | Exercise Habit Loop With Travel Disruption moderate personal problem: exercise habit loop with travel disruption | 3 | View → |
| chini-train-train-0048-dp3-civic | PC4 | Election-Day Polling Place Flow moderate civic problem: election-day polling place flow | 3 | View → |
| chini-train-train-0049-dp3-adversarial | PC5 | Free-Tier Signup Under Throwaway-Account Flood moderate adversarial problem: free-tier signup under throwaway-account flood | 3 | View → |
| chini-train-train-0050-dp3-infra | PC1 | Session-Store With Cache Stampede Risk moderate infra problem: session-store with cache stampede risk | 3 | View → |
| chini-train-train-0051-dp3-workflow | PC2 | Er Triage Queue Under Mass-Casualty Event moderate workflow problem: ER triage queue under mass-casualty event | 3 | View → |
| chini-train-train-0052-dp3-personal | PC3 | Inbox-Zero Workflow With Vacation Backlog moderate personal problem: inbox-zero workflow with vacation backlog | 3 | View → |
| chini-train-train-0053-dp3-civic | PC4 | Food-Bank Distribution Under Snap Delay moderate civic problem: food-bank distribution under SNAP delay | 3 | View → |
| chini-train-train-0054-dp3-adversarial | PC5 | Support-Chatbot Under Prompt-Injection Attempts moderate adversarial problem: support-chatbot under prompt-injection attempts | 3 | View → |
| chini-train-train-0055-dp3-infra | PC1 | Image Upload + Thumbnail Pipeline moderate infra problem: image upload + thumbnail pipeline | 3 | View → |
| chini-train-train-0056-dp3-workflow | PC2 | Restaurant Kitchen Ticket Flow moderate workflow problem: restaurant kitchen ticket flow | 3 | View → |
| chini-train-train-0057-dp3-personal | PC3 | Side-Project Momentum Across Weekends moderate personal problem: side-project momentum across weekends | 3 | View → |
| chini-train-train-0058-dp3-civic | PC4 | Transit-Card Refill Kiosks During Fare Change moderate civic problem: transit-card refill kiosks during fare change | 3 | View → |
| chini-train-train-0059-dp3-adversarial | PC5 | Rate-Limited Search Under Enumeration Attack moderate adversarial problem: rate-limited search under enumeration attack | 3 | View → |
| chini-train-train-0060-dp3-infra | PC1 | Rate-Limited Public Api Gateway moderate infra problem: rate-limited public API gateway | 3 | View → |
| chini-train-train-0061-dp3-workflow | PC2 | Airport Security Checkpoint Surge moderate workflow problem: airport security checkpoint surge | 3 | View → |
| chini-train-train-0062-dp3-personal | PC3 | Morning Routine When Alarm Fails moderate personal problem: morning routine when alarm fails | 3 | View → |
| chini-train-train-0063-dp3-civic | PC4 | 311 Call Center During Snowstorm moderate civic problem: 311 call center during snowstorm | 3 | View → |
| chini-train-train-0064-dp3-adversarial | PC5 | Login Endpoint Under Credential-Stuffing Burst moderate adversarial problem: login endpoint under credential-stuffing burst | 3 | View → |
| chini-train-train-0065-dp3-infra | PC1 | Pub-Sub Broker With Replay moderate infra problem: pub-sub broker with replay | 3 | View → |
| chini-train-train-0066-dp3-workflow | PC2 | Vaccine Cold-Chain Handoff moderate workflow problem: vaccine cold-chain handoff | 3 | View → |
| chini-train-train-0067-dp3-personal | PC3 | Weekly Meal-Prep Pipeline With One Bad Ingredient moderate personal problem: weekly meal-prep pipeline with one bad ingredient | 3 | View → |
| chini-train-train-0068-dp3-civic | PC4 | Dmv Appointment System At Month-End moderate civic problem: DMV appointment system at month-end | 3 | View → |
| chini-train-train-0069-dp3-adversarial | PC5 | Comment System Under Spam-Bot Wave moderate adversarial problem: comment system under spam-bot wave | 3 | View → |
| chini-train-train-0070-dp3-infra | PC1 | Search Autocomplete Service moderate infra problem: search autocomplete service | 3 | View → |
| chini-train-train-0071-dp3-workflow | PC2 | Dental-Clinic Appointment Ladder moderate workflow problem: dental-clinic appointment ladder | 3 | View → |
| chini-train-train-0072-dp3-personal | PC3 | Study Schedule With Willpower Drain moderate personal problem: study schedule with willpower drain | 3 | View → |
| chini-train-train-0073-dp3-civic | PC4 | Public-Library E-Book Hold Queue moderate civic problem: public-library e-book hold queue | 3 | View → |
| chini-train-train-0074-dp3-adversarial | PC5 | Ticket-Purchase Under Scalper-Bot Scrape moderate adversarial problem: ticket-purchase under scalper-bot scrape | 3 | View → |
| chini-train-train-0075-dp3-infra | PC1 | Feature-Flag Evaluation Service moderate infra problem: feature-flag evaluation service | 3 | View → |
| chini-train-train-0076-dp3-workflow | PC2 | Barber-Shop Walk-In Queue moderate workflow problem: barber-shop walk-in queue | 3 | View → |
| chini-train-train-0077-dp3-personal | PC3 | Exercise Habit Loop With Travel Disruption moderate personal problem: exercise habit loop with travel disruption | 3 | View → |
| chini-train-train-0078-dp3-civic | PC4 | Election-Day Polling Place Flow moderate civic problem: election-day polling place flow | 3 | View → |
| chini-train-train-0079-dp3-adversarial | PC5 | Free-Tier Signup Under Throwaway-Account Flood moderate adversarial problem: free-tier signup under throwaway-account flood | 3 | View → |
| chini-train-train-0080-dp3-infra | PC1 | Url Shortener moderate infra problem: URL shortener | 3 | View → |
| chini-train-train-0081-dp3-workflow | PC2 | Coffee-Shop Order Pipeline At Morning Rush moderate workflow problem: coffee-shop order pipeline at morning rush | 3 | View → |
| chini-train-train-0082-dp3-personal | PC3 | Inbox-Zero Workflow With Vacation Backlog moderate personal problem: inbox-zero workflow with vacation backlog | 3 | View → |
| chini-train-train-0083-dp3-civic | PC4 | Food-Bank Distribution Under Snap Delay moderate civic problem: food-bank distribution under SNAP delay | 3 | View → |
| chini-train-train-0084-dp3-adversarial | PC5 | Support-Chatbot Under Prompt-Injection Attempts moderate adversarial problem: support-chatbot under prompt-injection attempts | 3 | View → |
| chini-train-train-0085-dp3-infra | PC1 | In-App Notifications Fanout moderate infra problem: in-app notifications fanout | 3 | View → |
| chini-train-train-0086-dp3-workflow | PC2 | Warehouse Picking Line With Single Packer Bottleneck moderate workflow problem: warehouse picking line with single packer bottleneck | 3 | View → |
| chini-train-train-0087-dp3-personal | PC3 | Side-Project Momentum Across Weekends moderate personal problem: side-project momentum across weekends | 3 | View → |
| chini-train-train-0088-dp3-civic | PC4 | Transit-Card Refill Kiosks During Fare Change moderate civic problem: transit-card refill kiosks during fare change | 3 | View → |
| chini-train-train-0089-dp3-adversarial | PC5 | Rate-Limited Search Under Enumeration Attack moderate adversarial problem: rate-limited search under enumeration attack | 3 | View → |
| chini-train-train-0090-dp3-infra | PC1 | Session-Store With Cache Stampede Risk moderate infra problem: session-store with cache stampede risk | 3 | View → |
| chini-train-train-0091-dp3-workflow | PC2 | Er Triage Queue Under Mass-Casualty Event moderate workflow problem: ER triage queue under mass-casualty event | 3 | View → |
| chini-train-train-0092-dp3-personal | PC3 | Morning Routine When Alarm Fails moderate personal problem: morning routine when alarm fails | 3 | View → |
| chini-train-train-0093-dp3-civic | PC4 | 311 Call Center During Snowstorm moderate civic problem: 311 call center during snowstorm | 3 | View → |
| chini-train-train-0094-dp3-adversarial | PC5 | Login Endpoint Under Credential-Stuffing Burst moderate adversarial problem: login endpoint under credential-stuffing burst | 3 | View → |
| chini-train-train-0095-dp3-infra | PC1 | Image Upload + Thumbnail Pipeline moderate infra problem: image upload + thumbnail pipeline | 3 | View → |
| chini-train-train-0096-dp3-workflow | PC2 | Restaurant Kitchen Ticket Flow moderate workflow problem: restaurant kitchen ticket flow | 3 | View → |
| chini-train-train-0097-dp3-personal | PC3 | Weekly Meal-Prep Pipeline With One Bad Ingredient moderate personal problem: weekly meal-prep pipeline with one bad ingredient | 3 | View → |
| chini-train-train-0098-dp3-civic | PC4 | Dmv Appointment System At Month-End moderate civic problem: DMV appointment system at month-end | 3 | View → |
| chini-train-train-0099-dp3-adversarial | PC5 | Comment System Under Spam-Bot Wave moderate adversarial problem: comment system under spam-bot wave | 3 | View → |
| chini-train-train-0100-dp4-infra | PC1 | Rate-Limited Public Api Gateway hard infra problem: rate-limited public API gateway | 4 | View → |
| chini-train-train-0101-dp4-workflow | PC2 | Airport Security Checkpoint Surge hard workflow problem: airport security checkpoint surge | 4 | View → |
| chini-train-train-0102-dp4-personal | PC3 | Study Schedule With Willpower Drain hard personal problem: study schedule with willpower drain | 4 | View → |
| chini-train-train-0103-dp4-civic | PC4 | Public-Library E-Book Hold Queue hard civic problem: public-library e-book hold queue | 4 | View → |
| chini-train-train-0104-dp4-adversarial | PC5 | Ticket-Purchase Under Scalper-Bot Scrape hard adversarial problem: ticket-purchase under scalper-bot scrape | 4 | View → |
| chini-train-train-0105-dp4-infra | PC1 | Pub-Sub Broker With Replay hard infra problem: pub-sub broker with replay | 4 | View → |
| chini-train-train-0106-dp4-workflow | PC2 | Vaccine Cold-Chain Handoff hard workflow problem: vaccine cold-chain handoff | 4 | View → |
| chini-train-train-0107-dp4-personal | PC3 | Exercise Habit Loop With Travel Disruption hard personal problem: exercise habit loop with travel disruption | 4 | View → |
| chini-train-train-0108-dp4-civic | PC4 | Election-Day Polling Place Flow hard civic problem: election-day polling place flow | 4 | View → |
| chini-train-train-0109-dp4-adversarial | PC5 | Free-Tier Signup Under Throwaway-Account Flood hard adversarial problem: free-tier signup under throwaway-account flood | 4 | View → |
| chini-train-train-0110-dp4-infra | PC1 | Search Autocomplete Service hard infra problem: search autocomplete service | 4 | View → |
| chini-train-train-0111-dp4-workflow | PC2 | Dental-Clinic Appointment Ladder hard workflow problem: dental-clinic appointment ladder | 4 | View → |
| chini-train-train-0112-dp4-personal | PC3 | Inbox-Zero Workflow With Vacation Backlog hard personal problem: inbox-zero workflow with vacation backlog | 4 | View → |
| chini-train-train-0113-dp4-civic | PC4 | Food-Bank Distribution Under Snap Delay hard civic problem: food-bank distribution under SNAP delay | 4 | View → |
| chini-train-train-0114-dp4-adversarial | PC5 | Support-Chatbot Under Prompt-Injection Attempts hard adversarial problem: support-chatbot under prompt-injection attempts | 4 | View → |
| chini-train-train-0115-dp4-infra | PC1 | Feature-Flag Evaluation Service hard infra problem: feature-flag evaluation service | 4 | View → |
| chini-train-train-0116-dp4-workflow | PC2 | Barber-Shop Walk-In Queue hard workflow problem: barber-shop walk-in queue | 4 | View → |
| chini-train-train-0117-dp4-personal | PC3 | Side-Project Momentum Across Weekends hard personal problem: side-project momentum across weekends | 4 | View → |
| chini-train-train-0118-dp4-civic | PC4 | Transit-Card Refill Kiosks During Fare Change hard civic problem: transit-card refill kiosks during fare change | 4 | View → |
| chini-train-train-0119-dp4-adversarial | PC5 | Rate-Limited Search Under Enumeration Attack hard adversarial problem: rate-limited search under enumeration attack | 4 | View → |
| chini-train-train-0120-dp4-infra | PC1 | Url Shortener hard infra problem: URL shortener | 4 | View → |
| chini-train-train-0121-dp4-workflow | PC2 | Coffee-Shop Order Pipeline At Morning Rush hard workflow problem: coffee-shop order pipeline at morning rush | 4 | View → |
| chini-train-train-0122-dp4-personal | PC3 | Morning Routine When Alarm Fails hard personal problem: morning routine when alarm fails | 4 | View → |
| chini-train-train-0123-dp4-civic | PC4 | 311 Call Center During Snowstorm hard civic problem: 311 call center during snowstorm | 4 | View → |
| chini-train-train-0124-dp4-adversarial | PC5 | Login Endpoint Under Credential-Stuffing Burst hard adversarial problem: login endpoint under credential-stuffing burst | 4 | View → |
| chini-train-train-0125-dp4-infra | PC1 | In-App Notifications Fanout hard infra problem: in-app notifications fanout | 4 | View → |
| chini-train-train-0126-dp4-workflow | PC2 | Warehouse Picking Line With Single Packer Bottleneck hard workflow problem: warehouse picking line with single packer bottleneck | 4 | View → |
| chini-train-train-0127-dp4-personal | PC3 | Weekly Meal-Prep Pipeline With One Bad Ingredient hard personal problem: weekly meal-prep pipeline with one bad ingredient | 4 | View → |
| chini-train-train-0128-dp4-civic | PC4 | Dmv Appointment System At Month-End hard civic problem: DMV appointment system at month-end | 4 | View → |
| chini-train-train-0129-dp4-adversarial | PC5 | Comment System Under Spam-Bot Wave hard adversarial problem: comment system under spam-bot wave | 4 | View → |
| chini-train-train-0130-dp4-infra | PC1 | Session-Store With Cache Stampede Risk hard infra problem: session-store with cache stampede risk | 4 | View → |
| chini-train-train-0131-dp4-workflow | PC2 | Er Triage Queue Under Mass-Casualty Event hard workflow problem: ER triage queue under mass-casualty event | 4 | View → |
| chini-train-train-0132-dp4-personal | PC3 | Study Schedule With Willpower Drain hard personal problem: study schedule with willpower drain | 4 | View → |
| chini-train-train-0133-dp4-civic | PC4 | Public-Library E-Book Hold Queue hard civic problem: public-library e-book hold queue | 4 | View → |
| chini-train-train-0134-dp4-adversarial | PC5 | Ticket-Purchase Under Scalper-Bot Scrape hard adversarial problem: ticket-purchase under scalper-bot scrape | 4 | View → |
| chini-train-train-0135-dp4-infra | PC1 | Image Upload + Thumbnail Pipeline hard infra problem: image upload + thumbnail pipeline | 4 | View → |
| chini-train-train-0136-dp4-workflow | PC2 | Restaurant Kitchen Ticket Flow hard workflow problem: restaurant kitchen ticket flow | 4 | View → |
| chini-train-train-0137-dp4-personal | PC3 | Exercise Habit Loop With Travel Disruption hard personal problem: exercise habit loop with travel disruption | 4 | View → |
| chini-train-train-0138-dp4-civic | PC4 | Election-Day Polling Place Flow hard civic problem: election-day polling place flow | 4 | View → |
| chini-train-train-0139-dp4-adversarial | PC5 | Free-Tier Signup Under Throwaway-Account Flood hard adversarial problem: free-tier signup under throwaway-account flood | 4 | View → |
| chini-train-train-0140-dp4-infra | PC1 | Rate-Limited Public Api Gateway hard infra problem: rate-limited public API gateway | 4 | View → |
| chini-train-train-0141-dp4-workflow | PC2 | Airport Security Checkpoint Surge hard workflow problem: airport security checkpoint surge | 4 | View → |
| chini-train-train-0142-dp4-personal | PC3 | Inbox-Zero Workflow With Vacation Backlog hard personal problem: inbox-zero workflow with vacation backlog | 4 | View → |
| chini-train-train-0143-dp4-civic | PC4 | Food-Bank Distribution Under Snap Delay hard civic problem: food-bank distribution under SNAP delay | 4 | View → |
| chini-train-train-0144-dp4-adversarial | PC5 | Support-Chatbot Under Prompt-Injection Attempts hard adversarial problem: support-chatbot under prompt-injection attempts | 4 | View → |
| chini-train-train-0145-dp4-infra | PC1 | Pub-Sub Broker With Replay hard infra problem: pub-sub broker with replay | 4 | View → |
| chini-train-train-0146-dp4-workflow | PC2 | Vaccine Cold-Chain Handoff hard workflow problem: vaccine cold-chain handoff | 4 | View → |
| chini-train-train-0147-dp4-personal | PC3 | Side-Project Momentum Across Weekends hard personal problem: side-project momentum across weekends | 4 | View → |
| chini-train-train-0148-dp4-civic | PC4 | Transit-Card Refill Kiosks During Fare Change hard civic problem: transit-card refill kiosks during fare change | 4 | View → |
| chini-train-train-0149-dp4-adversarial | PC5 | Rate-Limited Search Under Enumeration Attack hard adversarial problem: rate-limited search under enumeration attack | 4 | View → |
| chini-train-train-0150-dp4-infra | PC1 | Search Autocomplete Service hard infra problem: search autocomplete service | 4 | View → |
| chini-train-train-0151-dp4-workflow | PC2 | Dental-Clinic Appointment Ladder hard workflow problem: dental-clinic appointment ladder | 4 | View → |
| chini-train-train-0152-dp4-personal | PC3 | Morning Routine When Alarm Fails hard personal problem: morning routine when alarm fails | 4 | View → |
| chini-train-train-0153-dp4-civic | PC4 | 311 Call Center During Snowstorm hard civic problem: 311 call center during snowstorm | 4 | View → |
| chini-train-train-0154-dp4-adversarial | PC5 | Login Endpoint Under Credential-Stuffing Burst hard adversarial problem: login endpoint under credential-stuffing burst | 4 | View → |
| chini-train-train-0155-dp4-infra | PC1 | Feature-Flag Evaluation Service hard infra problem: feature-flag evaluation service | 4 | View → |
| chini-train-train-0156-dp4-workflow | PC2 | Barber-Shop Walk-In Queue hard workflow problem: barber-shop walk-in queue | 4 | View → |
| chini-train-train-0157-dp5-personal | PC3 | Weekly Meal-Prep Pipeline With One Bad Ingredient brutal personal problem: weekly meal-prep pipeline with one bad ingredient | 4 | View → |
| chini-train-train-0158-dp5-civic | PC4 | Dmv Appointment System At Month-End brutal civic problem: DMV appointment system at month-end | 4 | View → |
| chini-train-train-0159-dp5-adversarial | PC5 | Comment System Under Spam-Bot Wave brutal adversarial problem: comment system under spam-bot wave | 4 | View → |
| chini-train-train-0160-dp5-infra | PC1 | Url Shortener brutal infra problem: URL shortener | 4 | View → |
| chini-train-train-0161-dp5-workflow | PC2 | Coffee-Shop Order Pipeline At Morning Rush brutal workflow problem: coffee-shop order pipeline at morning rush | 4 | View → |
| chini-train-train-0162-dp5-personal | PC3 | Study Schedule With Willpower Drain brutal personal problem: study schedule with willpower drain | 4 | View → |
| chini-train-train-0163-dp5-civic | PC4 | Public-Library E-Book Hold Queue brutal civic problem: public-library e-book hold queue | 4 | View → |
| chini-train-train-0164-dp5-adversarial | PC5 | Ticket-Purchase Under Scalper-Bot Scrape brutal adversarial problem: ticket-purchase under scalper-bot scrape | 4 | View → |
| chini-train-train-0165-dp5-infra | PC1 | In-App Notifications Fanout brutal infra problem: in-app notifications fanout | 4 | View → |
| chini-train-train-0166-dp5-workflow | PC2 | Warehouse Picking Line With Single Packer Bottleneck brutal workflow problem: warehouse picking line with single packer bottleneck | 4 | View → |
| chini-train-train-0167-dp5-personal | PC3 | Exercise Habit Loop With Travel Disruption brutal personal problem: exercise habit loop with travel disruption | 4 | View → |
| chini-train-train-0168-dp5-civic | PC4 | Election-Day Polling Place Flow brutal civic problem: election-day polling place flow | 4 | View → |
| chini-train-train-0169-dp5-adversarial | PC5 | Free-Tier Signup Under Throwaway-Account Flood brutal adversarial problem: free-tier signup under throwaway-account flood | 4 | View → |
| chini-train-train-0170-dp5-infra | PC1 | Session-Store With Cache Stampede Risk brutal infra problem: session-store with cache stampede risk | 4 | View → |
| chini-train-train-0171-dp5-workflow | PC2 | Er Triage Queue Under Mass-Casualty Event brutal workflow problem: ER triage queue under mass-casualty event | 4 | View → |
| chini-train-train-0172-dp5-personal | PC3 | Inbox-Zero Workflow With Vacation Backlog brutal personal problem: inbox-zero workflow with vacation backlog | 4 | View → |
| chini-train-train-0173-dp5-civic | PC4 | Food-Bank Distribution Under Snap Delay brutal civic problem: food-bank distribution under SNAP delay | 4 | View → |
| chini-train-train-0174-dp5-adversarial | PC5 | Support-Chatbot Under Prompt-Injection Attempts brutal adversarial problem: support-chatbot under prompt-injection attempts | 4 | View → |
| chini-train-train-0175-dp5-infra | PC1 | Image Upload + Thumbnail Pipeline brutal infra problem: image upload + thumbnail pipeline | 4 | View → |
| chini-train-train-0176-dp5-workflow | PC2 | Restaurant Kitchen Ticket Flow brutal workflow problem: restaurant kitchen ticket flow | 4 | View → |
| chini-train-train-0177-dp5-personal | PC3 | Side-Project Momentum Across Weekends brutal personal problem: side-project momentum across weekends | 4 | View → |
| chini-train-train-0178-dp5-civic | PC4 | Transit-Card Refill Kiosks During Fare Change brutal civic problem: transit-card refill kiosks during fare change | 4 | View → |
| chini-train-train-0179-dp5-adversarial | PC5 | Rate-Limited Search Under Enumeration Attack brutal adversarial problem: rate-limited search under enumeration attack | 4 | View → |
| chini-train-train-0180-dp5-infra | PC1 | Rate-Limited Public Api Gateway brutal infra problem: rate-limited public API gateway | 4 | View → |
| chini-train-train-0181-dp5-workflow | PC2 | Airport Security Checkpoint Surge brutal workflow problem: airport security checkpoint surge | 4 | View → |
| chini-train-train-0182-dp5-personal | PC3 | Morning Routine When Alarm Fails brutal personal problem: morning routine when alarm fails | 4 | View → |
| chini-train-train-0183-dp5-civic | PC4 | 311 Call Center During Snowstorm brutal civic problem: 311 call center during snowstorm | 4 | View → |
| chini-train-train-0184-dp5-adversarial | PC5 | Login Endpoint Under Credential-Stuffing Burst brutal adversarial problem: login endpoint under credential-stuffing burst | 4 | View → |
| chini-train-train-0185-dp5-infra | PC1 | Pub-Sub Broker With Replay brutal infra problem: pub-sub broker with replay | 4 | View → |
| chini-train-train-0186-dp6-workflow | PC2 | Vaccine Cold-Chain Handoff adversarial workflow problem: vaccine cold-chain handoff | 5 | View → |
| chini-train-train-0187-dp6-personal | PC3 | Weekly Meal-Prep Pipeline With One Bad Ingredient adversarial personal problem: weekly meal-prep pipeline with one bad ingredient | 5 | View → |
| chini-train-train-0188-dp6-civic | PC4 | Dmv Appointment System At Month-End adversarial civic problem: DMV appointment system at month-end | 5 | View → |
| chini-train-train-0189-dp6-adversarial | PC5 | Comment System Under Spam-Bot Wave adversarial adversarial problem: comment system under spam-bot wave | 5 | View → |
| chini-train-train-0190-dp6-infra | PC1 | Search Autocomplete Service adversarial infra problem: search autocomplete service | 5 | View → |
| chini-train-train-0191-dp6-workflow | PC2 | Dental-Clinic Appointment Ladder adversarial workflow problem: dental-clinic appointment ladder | 5 | View → |
| chini-train-train-0192-dp6-personal | PC3 | Study Schedule With Willpower Drain adversarial personal problem: study schedule with willpower drain | 5 | View → |
| chini-train-train-0193-dp6-civic | PC4 | Public-Library E-Book Hold Queue adversarial civic problem: public-library e-book hold queue | 5 | View → |
| chini-train-train-0194-dp6-adversarial | PC5 | Ticket-Purchase Under Scalper-Bot Scrape adversarial adversarial problem: ticket-purchase under scalper-bot scrape | 5 | View → |
| chini-train-train-0195-dp6-infra | PC1 | Feature-Flag Evaluation Service adversarial infra problem: feature-flag evaluation service | 5 | View → |
| chini-train-train-0196-dp6-workflow | PC2 | Barber-Shop Walk-In Queue adversarial workflow problem: barber-shop walk-in queue | 5 | View → |
| chini-train-train-0197-dp6-personal | PC3 | Exercise Habit Loop With Travel Disruption adversarial personal problem: exercise habit loop with travel disruption | 5 | View → |
| chini-train-train-0198-dp6-civic | PC4 | Election-Day Polling Place Flow adversarial civic problem: election-day polling place flow | 5 | View → |
| chini-train-train-0199-dp6-adversarial | PC5 | Free-Tier Signup Under Throwaway-Account Flood adversarial adversarial problem: free-tier signup under throwaway-account flood | 5 | View → |
| chini-train-train-0200-dp1-infra | PC1 | Url Shortener trivial infra problem: URL shortener | 1 | View → |
| chini-train-train-0201-dp1-workflow | PC2 | Coffee-Shop Order Pipeline At Morning Rush trivial workflow problem: coffee-shop order pipeline at morning rush | 1 | View → |
| chini-train-train-0202-dp1-personal | PC3 | Morning Routine When Alarm Fails trivial personal problem: morning routine when alarm fails | 1 | View → |
| chini-train-train-0203-dp1-civic | PC4 | 311 Call Center During Snowstorm trivial civic problem: 311 call center during snowstorm | 1 | View → |
| chini-train-train-0204-dp1-adversarial | PC5 | Login Endpoint Under Credential-Stuffing Burst trivial adversarial problem: login endpoint under credential-stuffing burst | 1 | View → |
| chini-train-train-0205-dp1-infra | PC1 | In-App Notifications Fanout trivial infra problem: in-app notifications fanout | 1 | View → |
| chini-train-train-0206-dp1-workflow | PC2 | Warehouse Picking Line With Single Packer Bottleneck trivial workflow problem: warehouse picking line with single packer bottleneck | 1 | View → |
| chini-train-train-0207-dp1-personal | PC3 | Weekly Meal-Prep Pipeline With One Bad Ingredient trivial personal problem: weekly meal-prep pipeline with one bad ingredient | 1 | View → |
| chini-train-train-0208-dp1-civic | PC4 | Dmv Appointment System At Month-End trivial civic problem: DMV appointment system at month-end | 1 | View → |
| chini-train-train-0209-dp1-adversarial | PC5 | Comment System Under Spam-Bot Wave trivial adversarial problem: comment system under spam-bot wave | 1 | View → |
| chini-train-train-0210-dp1-infra | PC1 | Session-Store With Cache Stampede Risk trivial infra problem: session-store with cache stampede risk | 1 | View → |
| chini-train-train-0211-dp1-workflow | PC2 | Er Triage Queue Under Mass-Casualty Event trivial workflow problem: ER triage queue under mass-casualty event | 1 | View → |
| chini-train-train-0212-dp1-personal | PC3 | Study Schedule With Willpower Drain trivial personal problem: study schedule with willpower drain | 1 | View → |
| chini-train-train-0213-dp1-civic | PC4 | Public-Library E-Book Hold Queue trivial civic problem: public-library e-book hold queue | 1 | View → |
| chini-train-train-0214-dp2-adversarial | PC5 | Ticket-Purchase Under Scalper-Bot Scrape easy adversarial problem: ticket-purchase under scalper-bot scrape | 2 | View → |
| chini-train-train-0215-dp2-infra | PC1 | Image Upload + Thumbnail Pipeline easy infra problem: image upload + thumbnail pipeline | 2 | View → |
| chini-train-train-0216-dp2-workflow | PC2 | Restaurant Kitchen Ticket Flow easy workflow problem: restaurant kitchen ticket flow | 2 | View → |
| chini-train-train-0217-dp2-personal | PC3 | Exercise Habit Loop With Travel Disruption easy personal problem: exercise habit loop with travel disruption | 2 | View → |
| chini-train-train-0218-dp2-civic | PC4 | Election-Day Polling Place Flow easy civic problem: election-day polling place flow | 2 | View → |
| chini-train-train-0219-dp2-adversarial | PC5 | Free-Tier Signup Under Throwaway-Account Flood easy adversarial problem: free-tier signup under throwaway-account flood | 2 | View → |
| chini-train-train-0220-dp2-infra | PC1 | Rate-Limited Public Api Gateway easy infra problem: rate-limited public API gateway | 2 | View → |
| chini-train-train-0221-dp2-workflow | PC2 | Airport Security Checkpoint Surge easy workflow problem: airport security checkpoint surge | 2 | View → |
| chini-train-train-0222-dp2-personal | PC3 | Inbox-Zero Workflow With Vacation Backlog easy personal problem: inbox-zero workflow with vacation backlog | 2 | View → |
| chini-train-train-0223-dp2-civic | PC4 | Food-Bank Distribution Under Snap Delay easy civic problem: food-bank distribution under SNAP delay | 2 | View → |
| chini-train-train-0224-dp2-adversarial | PC5 | Support-Chatbot Under Prompt-Injection Attempts easy adversarial problem: support-chatbot under prompt-injection attempts | 2 | View → |
| chini-train-train-0225-dp2-infra | PC1 | Pub-Sub Broker With Replay easy infra problem: pub-sub broker with replay | 2 | View → |
| chini-train-train-0226-dp2-workflow | PC2 | Vaccine Cold-Chain Handoff easy workflow problem: vaccine cold-chain handoff | 2 | View → |
| chini-train-train-0227-dp2-personal | PC3 | Side-Project Momentum Across Weekends easy personal problem: side-project momentum across weekends | 2 | View → |
| chini-train-train-0228-dp2-civic | PC4 | Transit-Card Refill Kiosks During Fare Change easy civic problem: transit-card refill kiosks during fare change | 2 | View → |
| chini-train-train-0229-dp2-adversarial | PC5 | Rate-Limited Search Under Enumeration Attack easy adversarial problem: rate-limited search under enumeration attack | 2 | View → |
| chini-train-train-0230-dp2-infra | PC1 | Search Autocomplete Service easy infra problem: search autocomplete service | 2 | View → |
| chini-train-train-0231-dp2-workflow | PC2 | Dental-Clinic Appointment Ladder easy workflow problem: dental-clinic appointment ladder | 2 | View → |
| chini-train-train-0232-dp2-personal | PC3 | Morning Routine When Alarm Fails easy personal problem: morning routine when alarm fails | 2 | View → |
| chini-train-train-0233-dp2-civic | PC4 | 311 Call Center During Snowstorm easy civic problem: 311 call center during snowstorm | 2 | View → |
| chini-train-train-0234-dp2-adversarial | PC5 | Login Endpoint Under Credential-Stuffing Burst easy adversarial problem: login endpoint under credential-stuffing burst | 2 | View → |
| chini-train-train-0235-dp2-infra | PC1 | Feature-Flag Evaluation Service easy infra problem: feature-flag evaluation service | 2 | View → |
| chini-train-train-0236-dp2-workflow | PC2 | Barber-Shop Walk-In Queue easy workflow problem: barber-shop walk-in queue | 2 | View → |
| chini-train-train-0237-dp2-personal | PC3 | Weekly Meal-Prep Pipeline With One Bad Ingredient easy personal problem: weekly meal-prep pipeline with one bad ingredient | 2 | View → |
| chini-train-train-0238-dp2-civic | PC4 | Dmv Appointment System At Month-End easy civic problem: DMV appointment system at month-end | 2 | View → |
| chini-train-train-0239-dp2-adversarial | PC5 | Comment System Under Spam-Bot Wave easy adversarial problem: comment system under spam-bot wave | 2 | View → |
| chini-train-train-0240-dp2-infra | PC1 | Url Shortener easy infra problem: URL shortener | 2 | View → |
| chini-train-train-0241-dp2-workflow | PC2 | Coffee-Shop Order Pipeline At Morning Rush easy workflow problem: coffee-shop order pipeline at morning rush | 2 | View → |
| chini-train-train-0242-dp2-personal | PC3 | Study Schedule With Willpower Drain easy personal problem: study schedule with willpower drain | 2 | View → |
| chini-train-train-0243-dp3-civic | PC4 | Public-Library E-Book Hold Queue moderate civic problem: public-library e-book hold queue | 3 | View → |
| chini-train-train-0244-dp3-adversarial | PC5 | Ticket-Purchase Under Scalper-Bot Scrape moderate adversarial problem: ticket-purchase under scalper-bot scrape | 3 | View → |
| chini-train-train-0245-dp3-infra | PC1 | In-App Notifications Fanout moderate infra problem: in-app notifications fanout | 3 | View → |
| chini-train-train-0246-dp3-workflow | PC2 | Warehouse Picking Line With Single Packer Bottleneck moderate workflow problem: warehouse picking line with single packer bottleneck | 3 | View → |
| chini-train-train-0247-dp3-personal | PC3 | Exercise Habit Loop With Travel Disruption moderate personal problem: exercise habit loop with travel disruption | 3 | View → |
| chini-train-train-0248-dp3-civic | PC4 | Election-Day Polling Place Flow moderate civic problem: election-day polling place flow | 3 | View → |
| chini-train-train-0249-dp3-adversarial | PC5 | Free-Tier Signup Under Throwaway-Account Flood moderate adversarial problem: free-tier signup under throwaway-account flood | 3 | View → |
| chini-train-train-0250-dp3-infra | PC1 | Session-Store With Cache Stampede Risk moderate infra problem: session-store with cache stampede risk | 3 | View → |
| chini-train-train-0251-dp3-workflow | PC2 | Er Triage Queue Under Mass-Casualty Event moderate workflow problem: ER triage queue under mass-casualty event | 3 | View → |
| chini-train-train-0252-dp3-personal | PC3 | Inbox-Zero Workflow With Vacation Backlog moderate personal problem: inbox-zero workflow with vacation backlog | 3 | View → |
| chini-train-train-0253-dp3-civic | PC4 | Food-Bank Distribution Under Snap Delay moderate civic problem: food-bank distribution under SNAP delay | 3 | View → |
| chini-train-train-0254-dp3-adversarial | PC5 | Support-Chatbot Under Prompt-Injection Attempts moderate adversarial problem: support-chatbot under prompt-injection attempts | 3 | View → |
| chini-train-train-0255-dp3-infra | PC1 | Image Upload + Thumbnail Pipeline moderate infra problem: image upload + thumbnail pipeline | 3 | View → |
| chini-train-train-0256-dp3-workflow | PC2 | Restaurant Kitchen Ticket Flow moderate workflow problem: restaurant kitchen ticket flow | 3 | View → |
| chini-train-train-0257-dp3-personal | PC3 | Side-Project Momentum Across Weekends moderate personal problem: side-project momentum across weekends | 3 | View → |
| chini-train-train-0258-dp3-civic | PC4 | Transit-Card Refill Kiosks During Fare Change moderate civic problem: transit-card refill kiosks during fare change | 3 | View → |
| chini-train-train-0259-dp3-adversarial | PC5 | Rate-Limited Search Under Enumeration Attack moderate adversarial problem: rate-limited search under enumeration attack | 3 | View → |
| chini-train-train-0260-dp3-infra | PC1 | Rate-Limited Public Api Gateway moderate infra problem: rate-limited public API gateway | 3 | View → |
| chini-train-train-0261-dp3-workflow | PC2 | Airport Security Checkpoint Surge moderate workflow problem: airport security checkpoint surge | 3 | View → |
| chini-train-train-0262-dp3-personal | PC3 | Morning Routine When Alarm Fails moderate personal problem: morning routine when alarm fails | 3 | View → |
| chini-train-train-0263-dp3-civic | PC4 | 311 Call Center During Snowstorm moderate civic problem: 311 call center during snowstorm | 3 | View → |
| chini-train-train-0264-dp3-adversarial | PC5 | Login Endpoint Under Credential-Stuffing Burst moderate adversarial problem: login endpoint under credential-stuffing burst | 3 | View → |
| chini-train-train-0265-dp3-infra | PC1 | Pub-Sub Broker With Replay moderate infra problem: pub-sub broker with replay | 3 | View → |
| chini-train-train-0266-dp3-workflow | PC2 | Vaccine Cold-Chain Handoff moderate workflow problem: vaccine cold-chain handoff | 3 | View → |
| chini-train-train-0267-dp3-personal | PC3 | Weekly Meal-Prep Pipeline With One Bad Ingredient moderate personal problem: weekly meal-prep pipeline with one bad ingredient | 3 | View → |
| chini-train-train-0268-dp3-civic | PC4 | Dmv Appointment System At Month-End moderate civic problem: DMV appointment system at month-end | 3 | View → |
| chini-train-train-0269-dp3-adversarial | PC5 | Comment System Under Spam-Bot Wave moderate adversarial problem: comment system under spam-bot wave | 3 | View → |
| chini-train-train-0270-dp3-infra | PC1 | Search Autocomplete Service moderate infra problem: search autocomplete service | 3 | View → |
| chini-train-train-0271-dp3-workflow | PC2 | Dental-Clinic Appointment Ladder moderate workflow problem: dental-clinic appointment ladder | 3 | View → |
| chini-train-train-0272-dp3-personal | PC3 | Study Schedule With Willpower Drain moderate personal problem: study schedule with willpower drain | 3 | View → |
| chini-train-train-0273-dp3-civic | PC4 | Public-Library E-Book Hold Queue moderate civic problem: public-library e-book hold queue | 3 | View → |
| chini-train-train-0274-dp3-adversarial | PC5 | Ticket-Purchase Under Scalper-Bot Scrape moderate adversarial problem: ticket-purchase under scalper-bot scrape | 3 | View → |
| chini-train-train-0275-dp3-infra | PC1 | Feature-Flag Evaluation Service moderate infra problem: feature-flag evaluation service | 3 | View → |
| chini-train-train-0276-dp3-workflow | PC2 | Barber-Shop Walk-In Queue moderate workflow problem: barber-shop walk-in queue | 3 | View → |
| chini-train-train-0277-dp3-personal | PC3 | Exercise Habit Loop With Travel Disruption moderate personal problem: exercise habit loop with travel disruption | 3 | View → |
| chini-train-train-0278-dp3-civic | PC4 | Election-Day Polling Place Flow moderate civic problem: election-day polling place flow | 3 | View → |
| chini-train-train-0279-dp3-adversarial | PC5 | Free-Tier Signup Under Throwaway-Account Flood moderate adversarial problem: free-tier signup under throwaway-account flood | 3 | View → |
| chini-train-train-0280-dp3-infra | PC1 | Url Shortener moderate infra problem: URL shortener | 3 | View → |
| chini-train-train-0281-dp3-workflow | PC2 | Coffee-Shop Order Pipeline At Morning Rush moderate workflow problem: coffee-shop order pipeline at morning rush | 3 | View → |
| chini-train-train-0282-dp3-personal | PC3 | Inbox-Zero Workflow With Vacation Backlog moderate personal problem: inbox-zero workflow with vacation backlog | 3 | View → |
| chini-train-train-0283-dp3-civic | PC4 | Food-Bank Distribution Under Snap Delay moderate civic problem: food-bank distribution under SNAP delay | 3 | View → |
| chini-train-train-0284-dp3-adversarial | PC5 | Support-Chatbot Under Prompt-Injection Attempts moderate adversarial problem: support-chatbot under prompt-injection attempts | 3 | View → |
| chini-train-train-0285-dp3-infra | PC1 | In-App Notifications Fanout moderate infra problem: in-app notifications fanout | 3 | View → |
| chini-train-train-0286-dp3-workflow | PC2 | Warehouse Picking Line With Single Packer Bottleneck moderate workflow problem: warehouse picking line with single packer bottleneck | 3 | View → |
| chini-train-train-0287-dp3-personal | PC3 | Side-Project Momentum Across Weekends moderate personal problem: side-project momentum across weekends | 3 | View → |
| chini-train-train-0288-dp3-civic | PC4 | Transit-Card Refill Kiosks During Fare Change moderate civic problem: transit-card refill kiosks during fare change | 3 | View → |
| chini-train-train-0289-dp3-adversarial | PC5 | Rate-Limited Search Under Enumeration Attack moderate adversarial problem: rate-limited search under enumeration attack | 3 | View → |
| chini-train-train-0290-dp3-infra | PC1 | Session-Store With Cache Stampede Risk moderate infra problem: session-store with cache stampede risk | 3 | View → |
| chini-train-train-0291-dp3-workflow | PC2 | Er Triage Queue Under Mass-Casualty Event moderate workflow problem: ER triage queue under mass-casualty event | 3 | View → |
| chini-train-train-0292-dp3-personal | PC3 | Morning Routine When Alarm Fails moderate personal problem: morning routine when alarm fails | 3 | View → |
| chini-train-train-0293-dp3-civic | PC4 | 311 Call Center During Snowstorm moderate civic problem: 311 call center during snowstorm | 3 | View → |
| chini-train-train-0294-dp3-adversarial | PC5 | Login Endpoint Under Credential-Stuffing Burst moderate adversarial problem: login endpoint under credential-stuffing burst | 3 | View → |
| chini-train-train-0295-dp3-infra | PC1 | Image Upload + Thumbnail Pipeline moderate infra problem: image upload + thumbnail pipeline | 3 | View → |
| chini-train-train-0296-dp3-workflow | PC2 | Restaurant Kitchen Ticket Flow moderate workflow problem: restaurant kitchen ticket flow | 3 | View → |
| chini-train-train-0297-dp3-personal | PC3 | Weekly Meal-Prep Pipeline With One Bad Ingredient moderate personal problem: weekly meal-prep pipeline with one bad ingredient | 3 | View → |
| chini-train-train-0298-dp3-civic | PC4 | Dmv Appointment System At Month-End moderate civic problem: DMV appointment system at month-end | 3 | View → |
| chini-train-train-0299-dp3-adversarial | PC5 | Comment System Under Spam-Bot Wave moderate adversarial problem: comment system under spam-bot wave | 3 | View → |
| chini-train-train-0300-dp4-infra | PC1 | Rate-Limited Public Api Gateway hard infra problem: rate-limited public API gateway | 4 | View → |
| chini-train-train-0301-dp4-workflow | PC2 | Airport Security Checkpoint Surge hard workflow problem: airport security checkpoint surge | 4 | View → |
| chini-train-train-0302-dp4-personal | PC3 | Study Schedule With Willpower Drain hard personal problem: study schedule with willpower drain | 4 | View → |
| chini-train-train-0303-dp4-civic | PC4 | Public-Library E-Book Hold Queue hard civic problem: public-library e-book hold queue | 4 | View → |
| chini-train-train-0304-dp4-adversarial | PC5 | Ticket-Purchase Under Scalper-Bot Scrape hard adversarial problem: ticket-purchase under scalper-bot scrape | 4 | View → |
| chini-train-train-0305-dp4-infra | PC1 | Pub-Sub Broker With Replay hard infra problem: pub-sub broker with replay | 4 | View → |
| chini-train-train-0306-dp4-workflow | PC2 | Vaccine Cold-Chain Handoff hard workflow problem: vaccine cold-chain handoff | 4 | View → |
| chini-train-train-0307-dp4-personal | PC3 | Exercise Habit Loop With Travel Disruption hard personal problem: exercise habit loop with travel disruption | 4 | View → |
| chini-train-train-0308-dp4-civic | PC4 | Election-Day Polling Place Flow hard civic problem: election-day polling place flow | 4 | View → |
| chini-train-train-0309-dp4-adversarial | PC5 | Free-Tier Signup Under Throwaway-Account Flood hard adversarial problem: free-tier signup under throwaway-account flood | 4 | View → |
| chini-train-train-0310-dp4-infra | PC1 | Search Autocomplete Service hard infra problem: search autocomplete service | 4 | View → |
| chini-train-train-0311-dp4-workflow | PC2 | Dental-Clinic Appointment Ladder hard workflow problem: dental-clinic appointment ladder | 4 | View → |
| chini-train-train-0312-dp4-personal | PC3 | Inbox-Zero Workflow With Vacation Backlog hard personal problem: inbox-zero workflow with vacation backlog | 4 | View → |
| chini-train-train-0313-dp4-civic | PC4 | Food-Bank Distribution Under Snap Delay hard civic problem: food-bank distribution under SNAP delay | 4 | View → |
| chini-train-train-0314-dp4-adversarial | PC5 | Support-Chatbot Under Prompt-Injection Attempts hard adversarial problem: support-chatbot under prompt-injection attempts | 4 | View → |
| chini-train-train-0315-dp4-infra | PC1 | Feature-Flag Evaluation Service hard infra problem: feature-flag evaluation service | 4 | View → |
| chini-train-train-0316-dp4-workflow | PC2 | Barber-Shop Walk-In Queue hard workflow problem: barber-shop walk-in queue | 4 | View → |
| chini-train-train-0317-dp4-personal | PC3 | Side-Project Momentum Across Weekends hard personal problem: side-project momentum across weekends | 4 | View → |
| chini-train-train-0318-dp4-civic | PC4 | Transit-Card Refill Kiosks During Fare Change hard civic problem: transit-card refill kiosks during fare change | 4 | View → |
| chini-train-train-0319-dp4-adversarial | PC5 | Rate-Limited Search Under Enumeration Attack hard adversarial problem: rate-limited search under enumeration attack | 4 | View → |
| chini-train-train-0320-dp4-infra | PC1 | Url Shortener hard infra problem: URL shortener | 4 | View → |
| chini-train-train-0321-dp4-workflow | PC2 | Coffee-Shop Order Pipeline At Morning Rush hard workflow problem: coffee-shop order pipeline at morning rush | 4 | View → |
| chini-train-train-0322-dp4-personal | PC3 | Morning Routine When Alarm Fails hard personal problem: morning routine when alarm fails | 4 | View → |
| chini-train-train-0323-dp4-civic | PC4 | 311 Call Center During Snowstorm hard civic problem: 311 call center during snowstorm | 4 | View → |
| chini-train-train-0324-dp4-adversarial | PC5 | Login Endpoint Under Credential-Stuffing Burst hard adversarial problem: login endpoint under credential-stuffing burst | 4 | View → |
| chini-train-train-0325-dp4-infra | PC1 | In-App Notifications Fanout hard infra problem: in-app notifications fanout | 4 | View → |
| chini-train-train-0326-dp4-workflow | PC2 | Warehouse Picking Line With Single Packer Bottleneck hard workflow problem: warehouse picking line with single packer bottleneck | 4 | View → |
| chini-train-train-0327-dp4-personal | PC3 | Weekly Meal-Prep Pipeline With One Bad Ingredient hard personal problem: weekly meal-prep pipeline with one bad ingredient | 4 | View → |
| chini-train-train-0328-dp4-civic | PC4 | Dmv Appointment System At Month-End hard civic problem: DMV appointment system at month-end | 4 | View → |
| chini-train-train-0329-dp4-adversarial | PC5 | Comment System Under Spam-Bot Wave hard adversarial problem: comment system under spam-bot wave | 4 | View → |
| chini-train-train-0330-dp4-infra | PC1 | Session-Store With Cache Stampede Risk hard infra problem: session-store with cache stampede risk | 4 | View → |
| chini-train-train-0331-dp4-workflow | PC2 | Er Triage Queue Under Mass-Casualty Event hard workflow problem: ER triage queue under mass-casualty event | 4 | View → |
| chini-train-train-0332-dp4-personal | PC3 | Study Schedule With Willpower Drain hard personal problem: study schedule with willpower drain | 4 | View → |
| chini-train-train-0333-dp4-civic | PC4 | Public-Library E-Book Hold Queue hard civic problem: public-library e-book hold queue | 4 | View → |
| chini-train-train-0334-dp4-adversarial | PC5 | Ticket-Purchase Under Scalper-Bot Scrape hard adversarial problem: ticket-purchase under scalper-bot scrape | 4 | View → |
| chini-train-train-0335-dp4-infra | PC1 | Image Upload + Thumbnail Pipeline hard infra problem: image upload + thumbnail pipeline | 4 | View → |
| chini-train-train-0336-dp4-workflow | PC2 | Restaurant Kitchen Ticket Flow hard workflow problem: restaurant kitchen ticket flow | 4 | View → |
| chini-train-train-0337-dp4-personal | PC3 | Exercise Habit Loop With Travel Disruption hard personal problem: exercise habit loop with travel disruption | 4 | View → |
| chini-train-train-0338-dp4-civic | PC4 | Election-Day Polling Place Flow hard civic problem: election-day polling place flow | 4 | View → |
| chini-train-train-0339-dp4-adversarial | PC5 | Free-Tier Signup Under Throwaway-Account Flood hard adversarial problem: free-tier signup under throwaway-account flood | 4 | View → |
| chini-train-train-0340-dp4-infra | PC1 | Rate-Limited Public Api Gateway hard infra problem: rate-limited public API gateway | 4 | View → |
| chini-train-train-0341-dp4-workflow | PC2 | Airport Security Checkpoint Surge hard workflow problem: airport security checkpoint surge | 4 | View → |
| chini-train-train-0342-dp4-personal | PC3 | Inbox-Zero Workflow With Vacation Backlog hard personal problem: inbox-zero workflow with vacation backlog | 4 | View → |
| chini-train-train-0343-dp4-civic | PC4 | Food-Bank Distribution Under Snap Delay hard civic problem: food-bank distribution under SNAP delay | 4 | View → |
| chini-train-train-0344-dp4-adversarial | PC5 | Support-Chatbot Under Prompt-Injection Attempts hard adversarial problem: support-chatbot under prompt-injection attempts | 4 | View → |
| chini-train-train-0345-dp4-infra | PC1 | Pub-Sub Broker With Replay hard infra problem: pub-sub broker with replay | 4 | View → |
| chini-train-train-0346-dp4-workflow | PC2 | Vaccine Cold-Chain Handoff hard workflow problem: vaccine cold-chain handoff | 4 | View → |
| chini-train-train-0347-dp4-personal | PC3 | Side-Project Momentum Across Weekends hard personal problem: side-project momentum across weekends | 4 | View → |
| chini-train-train-0348-dp4-civic | PC4 | Transit-Card Refill Kiosks During Fare Change hard civic problem: transit-card refill kiosks during fare change | 4 | View → |
| chini-train-train-0349-dp4-adversarial | PC5 | Rate-Limited Search Under Enumeration Attack hard adversarial problem: rate-limited search under enumeration attack | 4 | View → |
| chini-train-train-0350-dp4-infra | PC1 | Search Autocomplete Service hard infra problem: search autocomplete service | 4 | View → |
| chini-train-train-0351-dp4-workflow | PC2 | Dental-Clinic Appointment Ladder hard workflow problem: dental-clinic appointment ladder | 4 | View → |
| chini-train-train-0352-dp4-personal | PC3 | Morning Routine When Alarm Fails hard personal problem: morning routine when alarm fails | 4 | View → |
| chini-train-train-0353-dp4-civic | PC4 | 311 Call Center During Snowstorm hard civic problem: 311 call center during snowstorm | 4 | View → |
| chini-train-train-0354-dp4-adversarial | PC5 | Login Endpoint Under Credential-Stuffing Burst hard adversarial problem: login endpoint under credential-stuffing burst | 4 | View → |
| chini-train-train-0355-dp4-infra | PC1 | Feature-Flag Evaluation Service hard infra problem: feature-flag evaluation service | 4 | View → |
| chini-train-train-0356-dp4-workflow | PC2 | Barber-Shop Walk-In Queue hard workflow problem: barber-shop walk-in queue | 4 | View → |
| chini-train-train-0357-dp5-personal | PC3 | Weekly Meal-Prep Pipeline With One Bad Ingredient brutal personal problem: weekly meal-prep pipeline with one bad ingredient | 5 | View → |
| chini-train-train-0358-dp5-civic | PC4 | Dmv Appointment System At Month-End brutal civic problem: DMV appointment system at month-end | 5 | View → |
| chini-train-train-0359-dp5-adversarial | PC5 | Comment System Under Spam-Bot Wave brutal adversarial problem: comment system under spam-bot wave | 5 | View → |
| chini-train-train-0360-dp5-infra | PC1 | Url Shortener brutal infra problem: URL shortener | 5 | View → |
| chini-train-train-0361-dp5-workflow | PC2 | Coffee-Shop Order Pipeline At Morning Rush brutal workflow problem: coffee-shop order pipeline at morning rush | 5 | View → |
| chini-train-train-0362-dp5-personal | PC3 | Study Schedule With Willpower Drain brutal personal problem: study schedule with willpower drain | 5 | View → |
| chini-train-train-0363-dp5-civic | PC4 | Public-Library E-Book Hold Queue brutal civic problem: public-library e-book hold queue | 5 | View → |
| chini-train-train-0364-dp5-adversarial | PC5 | Ticket-Purchase Under Scalper-Bot Scrape brutal adversarial problem: ticket-purchase under scalper-bot scrape | 5 | View → |
| chini-train-train-0365-dp5-infra | PC1 | In-App Notifications Fanout brutal infra problem: in-app notifications fanout | 5 | View → |
| chini-train-train-0366-dp5-workflow | PC2 | Warehouse Picking Line With Single Packer Bottleneck brutal workflow problem: warehouse picking line with single packer bottleneck | 5 | View → |
| chini-train-train-0367-dp5-personal | PC3 | Exercise Habit Loop With Travel Disruption brutal personal problem: exercise habit loop with travel disruption | 5 | View → |
| chini-train-train-0368-dp5-civic | PC4 | Election-Day Polling Place Flow brutal civic problem: election-day polling place flow | 5 | View → |
| chini-train-train-0369-dp5-adversarial | PC5 | Free-Tier Signup Under Throwaway-Account Flood brutal adversarial problem: free-tier signup under throwaway-account flood | 5 | View → |
| chini-train-train-0370-dp5-infra | PC1 | Session-Store With Cache Stampede Risk brutal infra problem: session-store with cache stampede risk | 5 | View → |
| chini-train-train-0371-dp5-workflow | PC2 | Er Triage Queue Under Mass-Casualty Event brutal workflow problem: ER triage queue under mass-casualty event | 5 | View → |
| chini-train-train-0372-dp5-personal | PC3 | Inbox-Zero Workflow With Vacation Backlog brutal personal problem: inbox-zero workflow with vacation backlog | 5 | View → |
| chini-train-train-0373-dp5-civic | PC4 | Food-Bank Distribution Under Snap Delay brutal civic problem: food-bank distribution under SNAP delay | 5 | View → |
| chini-train-train-0374-dp5-adversarial | PC5 | Support-Chatbot Under Prompt-Injection Attempts brutal adversarial problem: support-chatbot under prompt-injection attempts | 5 | View → |
| chini-train-train-0375-dp5-infra | PC1 | Image Upload + Thumbnail Pipeline brutal infra problem: image upload + thumbnail pipeline | 5 | View → |
| chini-train-train-0376-dp5-workflow | PC2 | Restaurant Kitchen Ticket Flow brutal workflow problem: restaurant kitchen ticket flow | 5 | View → |
| chini-train-train-0377-dp5-personal | PC3 | Side-Project Momentum Across Weekends brutal personal problem: side-project momentum across weekends | 5 | View → |
| chini-train-train-0378-dp5-civic | PC4 | Transit-Card Refill Kiosks During Fare Change brutal civic problem: transit-card refill kiosks during fare change | 5 | View → |
| chini-train-train-0379-dp5-adversarial | PC5 | Rate-Limited Search Under Enumeration Attack brutal adversarial problem: rate-limited search under enumeration attack | 5 | View → |
| chini-train-train-0380-dp5-infra | PC1 | Rate-Limited Public Api Gateway brutal infra problem: rate-limited public API gateway | 5 | View → |
| chini-train-train-0381-dp5-workflow | PC2 | Airport Security Checkpoint Surge brutal workflow problem: airport security checkpoint surge | 5 | View → |
| chini-train-train-0382-dp5-personal | PC3 | Morning Routine When Alarm Fails brutal personal problem: morning routine when alarm fails | 5 | View → |
| chini-train-train-0383-dp5-civic | PC4 | 311 Call Center During Snowstorm brutal civic problem: 311 call center during snowstorm | 5 | View → |
| chini-train-train-0384-dp5-adversarial | PC5 | Login Endpoint Under Credential-Stuffing Burst brutal adversarial problem: login endpoint under credential-stuffing burst | 5 | View → |
| chini-train-train-0385-dp5-infra | PC1 | Pub-Sub Broker With Replay brutal infra problem: pub-sub broker with replay | 5 | View → |
| chini-train-train-0386-dp6-workflow | PC2 | Vaccine Cold-Chain Handoff adversarial workflow problem: vaccine cold-chain handoff | 6 | View → |
| chini-train-train-0387-dp6-personal | PC3 | Weekly Meal-Prep Pipeline With One Bad Ingredient adversarial personal problem: weekly meal-prep pipeline with one bad ingredient | 6 | View → |
| chini-train-train-0388-dp6-civic | PC4 | Dmv Appointment System At Month-End adversarial civic problem: DMV appointment system at month-end | 6 | View → |
| chini-train-train-0389-dp6-adversarial | PC5 | Comment System Under Spam-Bot Wave adversarial adversarial problem: comment system under spam-bot wave | 6 | View → |
| chini-train-train-0390-dp6-infra | PC1 | Search Autocomplete Service adversarial infra problem: search autocomplete service | 6 | View → |
| chini-train-train-0391-dp6-workflow | PC2 | Dental-Clinic Appointment Ladder adversarial workflow problem: dental-clinic appointment ladder | 6 | View → |
| chini-train-train-0392-dp6-personal | PC3 | Study Schedule With Willpower Drain adversarial personal problem: study schedule with willpower drain | 6 | View → |
| chini-train-train-0393-dp6-civic | PC4 | Public-Library E-Book Hold Queue adversarial civic problem: public-library e-book hold queue | 6 | View → |
| chini-train-train-0394-dp6-adversarial | PC5 | Ticket-Purchase Under Scalper-Bot Scrape adversarial adversarial problem: ticket-purchase under scalper-bot scrape | 6 | View → |
| chini-train-train-0395-dp6-infra | PC1 | Feature-Flag Evaluation Service adversarial infra problem: feature-flag evaluation service | 6 | View → |
| chini-train-train-0396-dp6-workflow | PC2 | Barber-Shop Walk-In Queue adversarial workflow problem: barber-shop walk-in queue | 6 | View → |
| chini-train-train-0397-dp6-personal | PC3 | Exercise Habit Loop With Travel Disruption adversarial personal problem: exercise habit loop with travel disruption | 6 | View → |
| chini-train-train-0398-dp6-civic | PC4 | Election-Day Polling Place Flow adversarial civic problem: election-day polling place flow | 6 | View → |
| chini-train-train-0399-dp6-adversarial | PC5 | Free-Tier Signup Under Throwaway-Account Flood adversarial adversarial problem: free-tier signup under throwaway-account flood | 6 | View → |
Appendix B: version history
| Version | Date | Changes |
|---|---|---|
| v0.7 | 2026-04-26 | Placement-aware design subscore. D1-D3 split into +10 (primitive present) and +15 (primitive on a source-to-sink forward path; for D2, upstream of the resolved outageTargetRole). D4 unchanged. Result JSONs gain optional designChecks.{queuePresence,resilience,rateDiscipline}.placed and .points fields; older v0.3 / v0.6 results are still accepted as-is. Every new result is stamped with meta.methodologyVersion = 0.7. Closes a v0.6-and-earlier gap flagged in public review where an orphaned queue scored the same as one inline on the flow. CLI / harness ids unchanged; existing leaderboard scores are not retro-graded, but anything submitted from this point forward is scored under v0.7.
|
| v0.6 | 2026-04-24 |
Added the multi-turn (agentic) track: POST /api/bench/feedback emits a redacted FeedbackPacket from the same simulator that grades the final submission, and chini-bench reflex run in the CLI does v1 generate -> feedback -> v2 generate -> submit in one call. Distinct harness id (chini-bench-reflex:42769353289d) so the leaderboard splits single-shot and multi-turn into separate tabs. First three-model multi-turn sweep (Claude Sonnet 4.6, GPT-5.4, Grok 4.20): 1 / 91 v2 passes. The CLI single-shot harness chini-bench-cli:06d0ffb42f19 is unchanged. Spec version jumped from v0.3 to v0.6 to align with the chini-bench CLI release that ships this track.
|
| v0.3 | 2026-04-23 |
Added 8 new problems (n=22 -> 30). Added design as a 5th subscore with 4 conditional structural checks (D1-D4). Added adversarial as a 5th scenario kind with two-pass scoring (attackBlockRate, cleanDeliveryRate). Wired OpenRouter; ran the first 4-model frontier sweep (Claude Sonnet 4.6, GPT-5.4, Grok 4.20, Gemini 3.1 Pro). Bumped max_tokens from 3000 to 12000 to accommodate thinking models.
|
| v0.2 | 2026-04-22 | 22 problems across 5 classes. Single-model baseline (Grok). Public CLI + dashboard launch. |
| v0.1 | 2026-04-22 | Internal pilot. 12 problems, PC1 + PC2 only. Established the simulator-as-judge protocol. |
References
- Shinn, N., Cassano, F., Berman, E., Gopinath, A., Narasimhan, K., & Yao, S. (2023). Reflexion: Language Agents with Verbal Reinforcement Learning. NeurIPS 2023. arXiv:2303.11366.
- Jimenez, C. E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., & Narasimhan, K. (2024). SWE-bench: Can Language Models Resolve Real-World GitHub Issues? ICLR 2024. arXiv:2310.06770.
Citation
If you reference CHINI-bench in academic or industry work, please cite it as:
@misc{chinibench2026,
title = {{CHINI-bench}: A simulator-graded benchmark for {AI} system design},
author = {Kwon, Alex},
year = {2026},
note = {Version 0.3. https://chinilla.com/bench},
url = {https://chinilla.com/bench}
} Plain text:
Kwon, A. (2026). CHINI-bench: A simulator-graded benchmark for AI system design (Version 0.3) [Benchmark]. https://chinilla.com/bench